
Le bout
Dans la partie 12 de cette série d'articles, j'annonçais m'attaquer à l'interprétation d'une ligne de Forth. Dans la partie 15... j'en vois le bout !
Forcément, avec la boucle QUIT, le mot INTERPRET forme le moteur de la partie interactive de Forth. Dans l'article précédent, j'avais énuméré tous les mots nécessaires à l'implémentation de NUMBER, élément manquant pour INTERPRET en mode d'interprétation (sans compilation). Et je terminais par si tout s'aligne parfaitement...
... quelques heures plus tard, en mettant au point NUMBER, je m'aperçois que je me suis trompé dans l'implémentation de DIGIT. Je n'avais pas écrit la signature en commentaire, codant de mémoire... et oubliant donc que la BASE qu'utilise DIGIT est un paramètre sur la pile, et non la variable directement. Ce fut vite corrigé.
J'ai aussi découvert que la chaîne du dictionnaire était cassée et que CFA était laissé de côté. Ce n'est pas la première fois que ça m'arrive, ni la première fois que je devrais trouver un test pour m'avertir, mais je ne l'ai toujours pas fait... Comme dans les tests je trouve les mots à appeler non par -FIND mais par leurs symboles assembleurs en direct, le fait qu'ils ne soient pas visibles dans le dictionnaire n'est pas détecté.
Et le test qui vérifie l'intégrité de la chaîne ne fait que cela, le test n'a pas la liste des mots qui devraient être trouvés, je trouvais ça un peu lourd à maintenir.
INTERPRET ! INTERPRET !
Tout cela fait, il est donc temps, ouf, ça y est, d'implémenter INTERPRET.
Le code (que je retravaille au fur et à mesure de l'implémentation réelle des mots) est actuellement celui-ci :
: INTERPRET
BEGIN
-FIND IF
DROP \ oublie la longueur du nom retourné par -FIND
CFA EXECUTE
ELSE
HERE NUMBER \ convertit en nombre
ENDIF
AGAIN ;
Ce code a un souci cependant... enfin deux. D'abord, il ne s'arrête pas à la fin du buffer. J'avais décidé dans le précédent article que -FIND laisserait une chaîne nulle dans HERE, mais je ne le teste pas encore.
Voici ce que cela peut donner :
: INTERPRET
BEGIN
-FIND IF
DROP \ oublie la longueur du nom retourné par -FIND
CFA EXECUTE
ELSE
HERE
C@ 0= IF EXIT THEN \ fin de la boucle, quitte le mot
HERE NUMBER \ convertit en nombre
ENDIF
AGAIN ;
Les mots EXIT et 0= n'existent pas pour le moment, mais étant donné que le mot est implémenté directement par une suite de CFA, 0BRANCH suffit.
Ni mot, ni nombre
Ensuite, il reste un dernier problème à régler : pour le moment, si -FIND ne trouve pas le mot dans le dictionnaire, alors c'est forcément un nombre ou la fin du buffer. Mais il est possible que le mot ne soit ni dans le dictionnaire, ni la représentation d'un nombre. Et dans ce cas, NUMBER pousse 0 sur la pile des paramètres. Ce n'est pas ce que l'on veut.
Pour détecter que l'on essaye de convertir en nombre une chaîne qui n'en est pas une représentation, voici ce que l'on trouve dans des sources :
(NUMBER)s'arrête au premier signe qui n'est pas considéré comme un chiffre valide et l'adresse mise à jour de la chaîne analysée se retrouve alors sur la pile.- On peut ajouter à
WORDle contrat suivant : il y a toujours un espace après le mot placé àHERE. - Si au retour de
(NUMBER),NUMBERdétecte autre chose qu'un espace à l'adresse retournée, alors une erreur est lancée, ce qui arrête l'interprétation. - Il faut ajouter un mot
ERRORqui provoque une erreur. Une erreur affiche le contenu présent àHEREsuivi d'un?puis branche surABORT, qui vide les piles (reset l'environnement plus généralement) et relance la boucleQUIT.
Le code Forth de ERROR est celui-ci :
: ERROR
HERE COUNT TYPE \ affiche le dernier mot
\ que WORD a mis en HERE
." ?" \ il n'y a pas de support de chaîne
\ pour le moment mais ça ressemblerait à ça
ABORT
; \ techniquement, il faut juste sortir du mode
\ compilation et rendre actif le mot. Mais
\ on n'a pas vu ça pour
\ le moment, donc je me contente d'un ;
Ça fonctionne !
J'ai dû corriger deux ou trois bugs sur le chemin (comme ACCEPT qui ne poussait pas la longueur du mot correctement sur la pile), mais voilà, ça fonctionne ! Je peux à présent simuler l'appui de touches depuis le harnais de test et vérifier le fonctionnement de l'interprétation à l'écran.
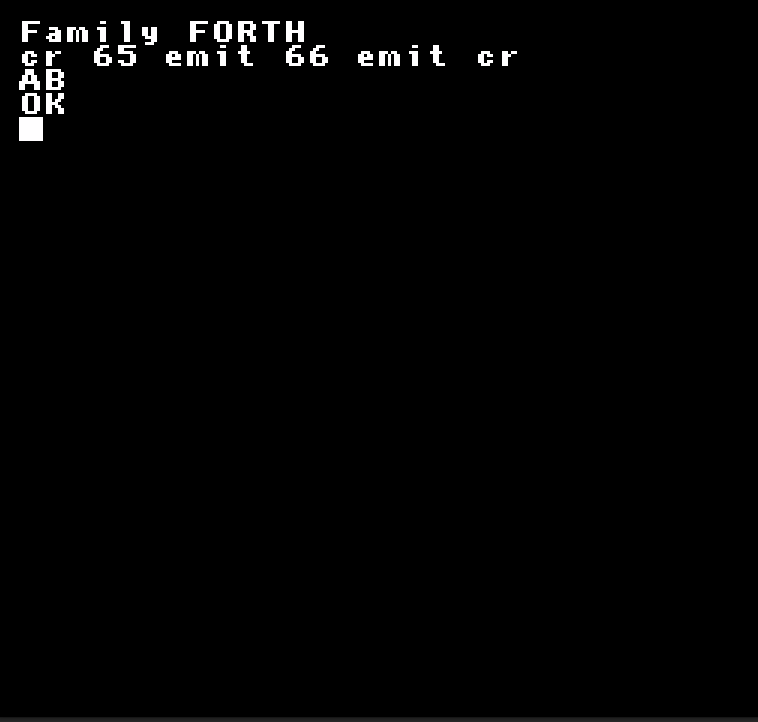
Je n'ai pas encore ., donc je ne peux pas afficher de résultat numérique, par contre, j'ai EMIT, et en ajoutant CR, je peux faire CR 65 EMIT 66 EMIT CR !
Et le test mémoire ?
Oui, ça y est, il est temps ! Il est temps d'utiliser un test avec écriture au clavier de HEX FF 7FF C! afin de capturer le changement mémoire depuis le harnais de tests et d'enlever le code en dur d'écriture mémoire qui existe depuis pratiquement le début de l'écriture de ce Forth.
MEMORY_TEST, TEST_VALUE et TEST_ADDR peuvent être supprimés du code et le test de Memory Watch remplacé par un test de Memory Watch à partir d'un test d'INTERPRET.
Pfiuu ! Quelle aventure !
Il est temps aussi de faire une petite pause de réflexion pour, déjà, passer à l'étape suivante : la création de mots, et donc la partie compilation d'INTERPRET.